메타플랫폼(이하 메타)이 자사의 최신 거대 언어 모델(LLM)인 라마4(Llama4)를 공개했다.
메타는 5일(현지시간) 블로그를 통해 라마4 제품군 중 ‘라마4 스카우트’와 ‘라마4 매버릭’을 선보인다고 밝혔다. ‘라마4 베히모스’는 아직 학습(훈련) 중인 것으로 알려졌다.
메타는 왓츠앱, 메신저, 인스타그램을 포함한 앱 전반의 AI 기반 어시스턴트인 메타 AI가 40개국에서 라마4를 사용하도록 업데이트됐다고 발표했다. 멀티모달 기능은 현재 영어로 미국에서만 제공된다.
메타의 내부 테스트에 따르면 창의적 글쓰기와 같은 ‘일반 보조 및 채팅’ 사용 사례에 가장 적합하다고 말하는 매버릭은 특정 코딩, 추론, 다국어, 장문 컨텍스트 및 이미지 벤치마크에서 OpenAI의 GPT-4o, 구글의 제미나이2.0 과 같은 모델을 능가한다.
다만 구글의 Gemini 2.5프로 , 앤트로픽의 클로드 3.7 소네트 및 OpenAI의 GPT-4.5 등 유능한 최신 모델에는 미치지 못했다.
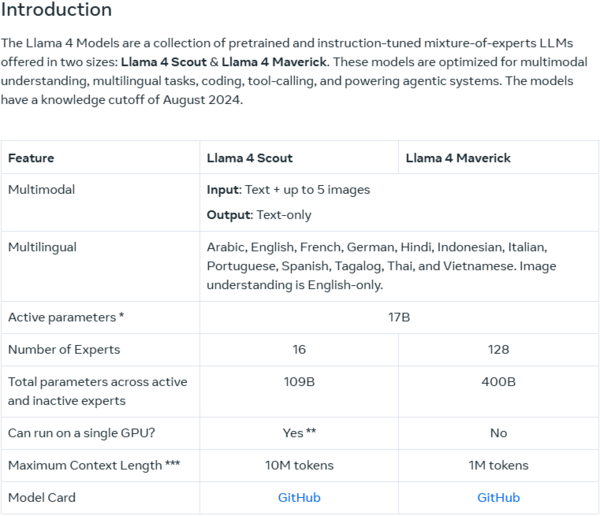
라마4 스카우트의 강점은 문서 요약 및 대규모 코드베이스에 대한 추론과 같은 작업에 강하다는 점이다. 라마4 스카우트는 1000만개의 토큰을 지원하는데 이는 질문시 논문 1000편 내외를 한 번에 질문할 수 있는 양이다.
메타는 라마4 스카우트와 매버릭이 지금까지 자사가 개발한 모델 중 ‘가장 진보한 버전’이며, 멀티모달 기능 면에서 ‘동급 최고 성능’을 자랑한다고 강조했다.
메타는 “라마4 스카우트는 긴 콘텍스트 처리 및 효율성에 중점을 두고 있고, 라마4 매버릭은 더 넓은 범위의 작업에서 높은 성능을 제공한다”며 “벤치마크 프로그램인 LM 아레나에서 높은 점수를 차지했다”고 설명했다.
다만 일부 외신 등에 따르면 메타가 발표한 라마4 매버릭의 벤치마크 점수는 신뢰성이 낮다. 테크크런치 등에 따르면 LM 아레나에 배포한 매버릭과 메타가 오픈소스로 배포한 매버릭의 버전이 다르다. 또한 LM 아레나 자체 신뢰도도 낮다는 입장이다.
메타는 라마 웹사이트를 통해 LM 아레나에서 테스트된 모델은 ‘대화 최적화’를 거친 실험 버전임을 알렸지만 일부 연구원들 사이에서 라마4가 LM 아레나에서는 답변이 장황해지고 이모티콘을 과도하게 사용한다고 지적하고 있다.
네이선 램버트 AI2 포스트트레이닝 연구원은 SNS X(구 트위터)를 통해 “라마4는 확실히 좀 이상하다. 너무 시끄럽다”고 말했다.