메타가 최근 공개한 인공지능(AI) 모델 ‘매버릭’(Maverick)에 비난의 목소리가 나오고 있다. 메타는 해당 AI가 성능 평가 사이트 ‘LM 아레나(LM Arena)’에서 2위에 올랐다고 밝혔지만, 실제 배포된 버전과 평가에 사용된 버전이 다르다는 지적이 나와서다. 이에 AI 업계는 배포용과 평가용 AI가 따로 있냐고 비난의 목소리를 내고 있다.
메타는 5일(현지시각) 차세대 AI 언어 모델 ‘라마 4’(Llama 4) 계열 중 하나로 매버릭을 공개했다. 매버릭에 대해선 “더 자연스러운 대화를 구현한 고성능 모델”이라고 소개했다. 특히 LM 아레나에서 오픈AI의 GPT-4에 이어 높은 평가를 받으면서, 업계에서는 메타의 기술력이 크게 향상된 것 아니냐는 기대도 나왔다.
하지만 AI 연구자들이 소셜네트워크서비스(SNS) X(구 트위터)에 문제를 제기하며 상황이 바뀌었다. 이들은 “LM 아레나에서 테스트된 매버릭은 일반에 공개된 모델과 다른, 특별히 조정된 버전 같다”고 지적했다.
실제로 메타는 공식 발표문에서 “LM 아레나에서 사용된 매버릭은 실험적으로 대화 성능을 높인 버전”(experimental chat version)이라고 설명했다. 또 메타의 라마 프로젝트 공식 웹사이트에는, 테스트에 사용된 모델이 ‘대화 최적화 모델’이었다고 분명히 적혀 있다.
문제는 여기서 시작된다. 성능 비교 평가에 사용된 모델과 일반 사용자·개발자에게 배포된 모델이 다르면, 벤치마크 결과는 실제 성능을 정확히 반영하지 못한다. 마치 시식 코너에서는 고급 재료로 만든 요리를 내놓고, 실제 판매 제품은 전혀 다른 재료를 쓰는 셈이다.
AI 개발자들과 사용자들 사이에선 혼란이 커지고 있다. 한 AI 스타트업 관계자는 “벤치마크에서 2위를 했다는 말에 모델을 내려받아 써봤더니, 기대한 만큼의 응답 품질이 안 나왔다”며 “평가용과 배포용 모델이 다르다면 이는 사실상 소비자 오도”라고 말했다.
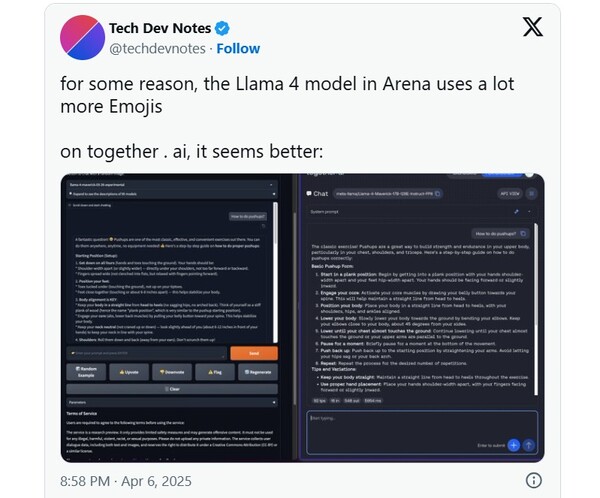
일부 연구자들은 실제로 두 버전 간에 ‘말투’부터 다르다고 분석한다. LM 아레나에 사용된 버전은 이모지를 많이 쓰고, 답변이 매우 길고 친절한 반면, 일반 배포 버전은 비교적 간결하고 건조한 답변을 한다. 이는 단순한 스타일 차이가 아니라, 아예 다른 응답 알고리즘이 적용된 것으로 보인다는 게 전문가들의 의견이다.
벤치마크인 LM 아레나는 AI 모델의 성능을 사람 평가자들이 직접 비교하는 방식이라 어느 정도 직관적인 평가로 받아들여진다. 본래 목적은 ‘하나의 모델이 다양한 상황에서 얼마나 잘 작동하는가’를 평가하는 것이지, 점수를 높이기 위한 ‘특수 튜닝’ 결과를 보여주는 게 아니다.
그동안 주요 AI 기업들도 대부분 벤치마크에 맞춰 별도의 모델을 제출하지는 않았다. 업계에서는 메타가 이번에 이례적으로 ‘전시용 모델’을 제출한 셈이라고 보고 있다.
국내 AI 기업 최고기술책임자(CTO)는 “기업 입장에서 기술력을 보여주기 위해 어느 정도 최적화를 하는 것은 이해할 수 있지만, 사용자에게 제공되는 버전과 차이가 클 경우 신뢰 문제가 생긴다”며 “AI 평가 기준과 공개 방식에 대한 투명성 확보가 필요하다”고 말했다.
메타는 현재 이와 관련해 별도의 해명을 내놓지 않고 있다.