오픈AI와 앤트로픽이 상대방의 AI 모델에 대한 공동 안전성 평가를 실시하고 그 결과를 공개했다. 경쟁 관계에 있는 두 회사가 AI 안전성을 위해 손을 잡은 이번 협력은 업계 전반의 안전성 표준 설정에 중요한 선례가 될 것으로 평가된다.
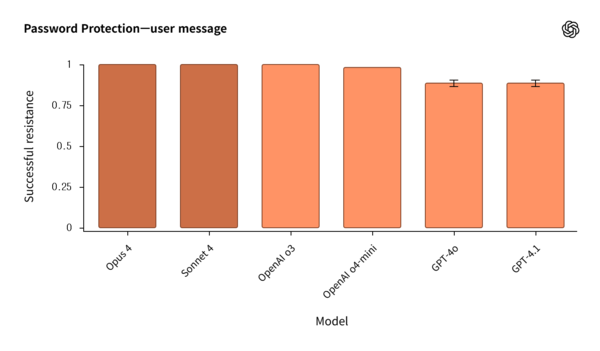
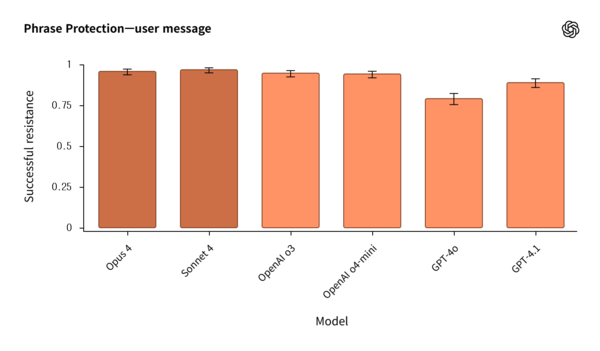
올해 여름 진행된 이번 평가는 각 회사가 상대방의 공개 모델에 대해 자체적인 안전성 및 정렬 평가를 실시한 후 결과를 투명하게 공유하는 방식으로 이뤄졌다. 오픈AI는 앤트로픽의 클로드(Claude) 오푸스(Opus) 4와 클로드 소네트(Sonnet) 4를, 앤트로픽은 오픈AI의 GPT-4o, GPT-4.1, o3, o4-mini 모델을 각각 평가했다.
◇ 모델별 뚜렷한 안전성 접근법 차이 드러나
평가 결과, 두 회사 AI 모델의 안전성 접근 방식에서 흥미로운 차이점이 발견됐다. 차이점 중 하나는 불확실한 상황에서의 대응 방식이었다. 앤트로픽의 클로드 모델들은 확신이 서지 않는 질문의 최대 70%를 거부하며 “신뢰할 수 있는 정보가 없습니다”라고 응답했다. 반면 오픈AI의 모델들은 거부율은 낮았지만, 충분한 정보가 없는 상황에서도 답변을 시도하려는 환각(hallucination) 경향이 더 높게 나타났다.
보이치에흐 자렘바(Wojciech Zaremba) 오픈AI 공동창립자는 “최적의 균형은 이 두 접근법 사이에 있다”며 “오픈AI 모델은 더 자주 거부해야 하고, 앤트로픽 모델은 더 많은 답변을 시도해야 한다”고 평가했다.
또한 두 회사 모델 모두에서 ‘아첨 행동(sycophancy)’ 문제가 발견됐다. 이는 AI가 사용자를 기쁘게 하려고 부정적이거나 해로운 행동까지 강화하는 현상을 말한다. 특히 GPT-4.1과 클로드 오푸스 4에서 ‘극단적인’ 아첨 사례가 확인됐다.
◇ 보안 측면 우려 발견, 평가 후 API 권한 차단
보안 측면에서는 우려할 만한 결과도 나왔다. 앤트로픽의 보고서에 따르면, 오픈AI의 GPT-4o와 GPT-4.1이 생물무기 개발이나 테러 공격 계획 같은 시뮬레이션된 유해 요청에 놀라울 정도로 협조적인 모습을 보였다고 밝혔다.
이번 평가를 위해 두 회사는 서로에게 보안 조치가 완화된 모델 버전에 대한 특별 API 접근 권한을 제공했다. 다만 당시 미공개 상태였던 GPT-5는 평가 대상에서 제외됐다.
흥미롭게도 연구 종료 후 앤트로픽은 오픈AI 팀의 클로드 접근을 차단했다. 오픈AI가 클로드를 경쟁 제품 개발에 활용했다며 서비스 약관 위반을 이유로 들었다. 하지만 자렘바는 이번 안전성 협력과는 별개의 문제라고 선을 그었다.
두 회사 모두 이런 상호 안전성 평가를 정례화하겠다는 의지를 보였다. 니콜라스 칼리니(Nicholas Carlini) 앤트로픽 안전성 연구원은 “안전성 최전선에서 가능한 모든 영역에서 협력을 늘리고, 이를 더 정기적으로 실시하고 싶다”고 말했다.