
“인공지능(AI)이 내 개인정보를 몰래 기억하고 있다면?” 이런 두려움이 현실이 되는 시대에 발맞춰 구글이 혁신적인 해답을 내놨다. 똑똑하게 일하면서 개인정보는 아예 기억조차 못 하는 AI인 ‘볼트젬마(VaultGemma)’를 출시했다. 병원 차트부터 은행 거래내역까지, 민감한 정보를 다루는 모든 곳에서 AI를 활용할 수 있는 기반이 될 것으로 전망된다.
◇ AI ‘건망증’에 걸리게 만들다
기존 AI의 치명적 약점은 학습 과정에서 본 개인정보를 그대로 외워버릴 수 있다는 점이었다. 마치 의사가 환자 차트를 보고 나중에 그 내용을 다른 사람에게 말해버리는 것과 같은 위험이 있었다.
구글이 12일(현지시각) 공개한 ‘볼트젬마’는 이 문제를 ‘차등 프라이버시’라는 기법으로 해결했다. AI가 학습할 때 의도적으로 ‘잡음’을 섞어 넣어서 개인의 구체적 정보는 기억하지 못하게 하되, 전체적인 언어 패턴은 여전히 배울 수 있게 만든 것이다. 실제 테스트에서 볼트젬마는 학습 때 봤던 문서 내용을 그대로 복사해서 말하지 못했다. 마치 책을 읽고 줄거리는 이해했지만, 정확한 문장은 기억 못 하는 사람처럼 행동한다.
볼트젬마는 10억 개의 정보 단위를 처리할 수 있는 대형 모델로, 개인정보를 보호하면서 처음부터 만든 공개 AI 중 가장 크다. 성능은 최신 AI보다는 떨어지지만, 5년 전 GPT-2와 비슷한 수준으로 실생활에서 충분히 활용 가능하다는 평가다.
◇ 수학적 잡음으로 개인정보만 골라 지운다
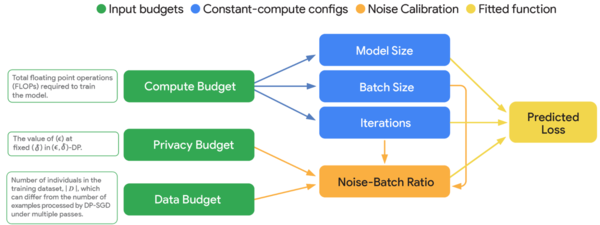
볼트젬마의 핵심 기술은 ‘노이즈-배치 비율’이라는 수학 공식에 있다. 학습 과정에서 개인정보 보호용 잡음의 양과 한 번에 처리하는 데이터 크기의 비율을 정밀하게 조절하는 것이다.
구체적으로는 1024개 토큰(정보 조각)으로 구성된 문서 단위별로 프라이버시를 보장한다. 만약 어떤 개인정보가 단 하나의 문서에만 나타난다면, 볼트젬마는 그 정보를 전혀 기억하지 못한다. 반대로 많은 문서에서 공통으로 나타나는 일반적 지식은 정상적으로 학습할 수 있다.
이를 위해 구글은 ‘푸아송 샘플링’이라는 특별한 데이터 처리 방식도 도입했다. 기존 방식으로는 같은 크기의 데이터 묶음으로만 학습할 수 있었지만, 이 방식을 통해 크기가 다른 데이터 묶음으로도 안전하게 학습할 수 있게 됐다.
구글 연구진은 수천 번의 실험을 통해 최적의 ‘노이즈-배치 비율’을 찾아냈다. 일반 AI와 달리 개인정보 보호 AI는 모델 크기를 작게 하되 한 번에 처리하는 데이터양을 크게 해야 효율적이라는 새로운 법칙도 발견했다.
◇ 병원·금융권에서 AI 혁명 시작된다
볼트젬마의 등장으로 개인정보가 생명인 분야에서도 AI 활용이 가능해질 것으로 전망된다. 병원에서는 환자 정보 유출 걱정 없이 AI로 진단을 도울 수 있고, 은행에서는 고객 데이터 보안을 지키면서 AI 서비스를 제공할 수 있어서다.
법무법인에서 의뢰인 정보를 다루거나, 학교에서 학생 기록을 관리할 때도 마찬가지다. 지금까지 개인정보 때문에 AI 도입을 주저했던 모든 분야에서 새로운 가능성이 열린 셈이다.
구글은 볼트젬마를 완전 무료로 공개했다. 허깅페이스, 캐글 등 AI 플랫폼에서 누구나 내려받아 쓸 수 있으며, 상세한 기술 문서도 함께 제공해 더 나은 모델 개발을 돕고 있다.
구글 연구진은 “볼트젬마는 강력한 성능과 완벽한 프라이버시 보호를 동시에 달성한 첫 번째 대형 AI”라며 “모든 사람이 안전하게 AI의 혜택을 누릴 수 있는 시대를 열겠다”고 밝혔다.