
AI 기술이 빠르게 발전하며 초거대 모델이 주목받고 있지만, 실제 산업 현장에서 더 시급한 사항은 지연, 연결성, 그리고 리소스 제약 등의 이슈이다. 데이터를 클라우드에만 의존하는 방식은 네트워크 지연과 보안 위험, 그리고 비용 증가라는 문제를 동반한다. 이로 인해 현장에서 즉각적인 의사결정을 내릴 수 있도록 AI를 단말 장치에 직접 배포하는, 이른바 엣지 AI(Edge AI)의 필요성이 커질 수밖에 없다.
◇ 엣지 AI가 필요한 이유
엣지 AI는 단순히 서버 성능을 옮겨놓는 개념이 아니다. 제한된 자원을 가진 MCU, 산업용 PC, 센서와 같은 하드웨어에서도 효율적으로 동작할 수 있도록 설계된 기술이다. 영상 검사, 예측 유지보수, 가상 센서, 모터 제어, 첨단 운전자 보조 시스템(Advanced Driver Assistance System, ADAS)과 같이 실시간 응답이 필수적인 분야에서 특히 강력한 효과를 발휘한다. 밀리초 단위 반응 속도가 요구되는 제어 및 안전 관련 시스템에서는 지연 없는 응답을 보장하고, 네트워크가 불안정하거나 클라우드 접속이 제한된 상황에서도 독립적으로 운영된다. 또한 민감한 데이터를 로컬에서 처리하기 때문에 보안성은 한층 강화되며, 클라우드 전송 및 서버 사용에 드는 비용을 크게 절감할 수 있다는 장점도 있다.
결국 엣지 AI는 단순한 성능 향상이 아니라 안전성, 경제성, 확장성을 동시에 제공하는 핵심 패러다임으로 자리매김하고 있다. 특히 자동차, 항공, 의료처럼 안전과 신뢰성이 절대적으로 요구되는 분야에서 엣지 AI는 신뢰할 수 있는 AI 배포를 가능하게 하는 기술적 기반이다. 앞으로의 지능형 시스템은 클라우드와 엣지를 혼합한 구조로 진화할 것이며, 그 중심에서 엣지 AI는 산업 현장의 실질적인 가치를 만들어내는 역할을 담당하게 될 것이다.
그러나 이러한 비전을 실현하기 위해서는 제약이 많은 엣지 하드웨어 환경에서도 무거운 AI 모델이 원활히 동작할 수 있도록 타깃 장비에 최적화하는 기술이 필요하다. 그런데 여기서 중요한 점은 산업 현장에서 요구하는 엣지 디바이스가 매우 다양하다는 것이다. MCU처럼 저전력 임베디드 시스템에서부터 산업용 CPU, GPU, FPGA, 그리고 최신 NPU까지, 플랫폼별 특성과 제약 조건에 따라 최적화 전략도 달라져야 한다. 매스웍스는 이러한 다양한 엣지 디바이스를 지원하는 솔루션을 제공하여, 산업 현장의 요구에 맞는 AI 모델 배포를 실현할 수 있도록 돕고 있다.
◇ 사영(Projection)과 양자화(Quantization)를 활용한 AI 모델 압축
이제 우리는 사영과 양자화를 활용한 AI 모델 압축이라는 주제를 통해, 엣지 AI의 현실화를 앞당기는 또 다른 열쇠를 살펴볼 필요가 있다. 모델 압축 기법은 크기와 복잡성을 줄이고 추론 속도를 향상시키며 전력 소모를 줄여 무거운 AI 모델을 엣지에 배포하는데 도움을 된다. 그러나 과도한 압축은 예측 품질을 저하시킬 수 있어, 엔지니어는 하드웨어 제약을 충족하기 위해 어느 정도의 정확도 손실을 감수할 수 있는지 신중히 평가해야 한다.
사영과 양자화라는 두 가지 상호 보완적인 압축 기술을 결합하여 엣지 솔루션에 최적화된 AI 모델을 구현할 수 있다. 사영은 중요한 특징을 유지하면서 모델의 차원을 낮춰 계산 복잡성을 줄이고, 양자화는 남은 파라미터를 낮은 정밀도의 정수형 데이터 타입으로 변환해 모델을 추가로 압축한다. 두 기술을 함께 활용하면 모델의 구조와 데이터 타입을 모두 압축할 수 있어, 정확도를 크게 저해하지 않으면서 효율성을 높일 수 있다. 일반적으로는 먼저 사영을 적용하여 모델의 구조를 압축한 후, 양자화를 통해 메모리 사용량과 연산 비용을 추가로 줄이는 방법이 권장된다.
사영은 매트랩의 딥러닝 툴박스(Deep Learning Toolbox)에서 제공되는 구조 압축 기법으로, 레이어의 가중치 행렬을 더 낮은 차원의 공간으로 투사하여 학습 가능한 파라미터 수를 줄이는데 사용할 수 있다. 이 기법은 주성분 분석(principal component analysis, 이하 PCA)을 기반으로 하며, 신경망 활성화 값의 분산이 가장 큰 방향을 식별하고, 고차원 가중치 행렬을 더 작고 효율적인 표현으로 근사하여 불필요한 파라미터를 제거한다. 이를 통해 메모리 및 연산 요구량을 줄이면서도 모델의 정확도와 표현력을 유지할 수 있다.
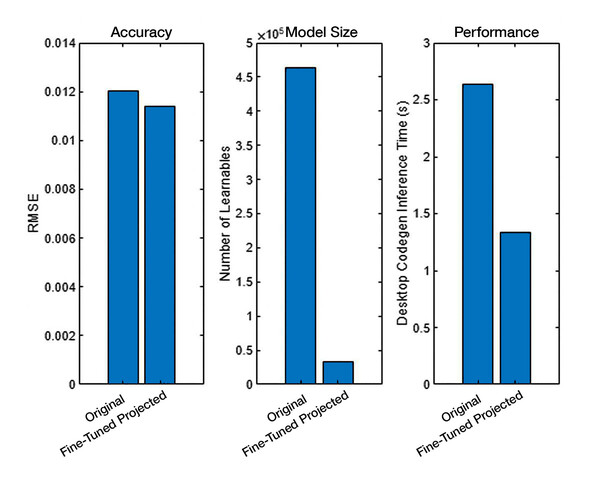
양자화는 데이터 타입 압축 기법으로, AI 모델의 학습 가능한 파라미터인 가중치와 바이어스를 고정밀 부동소수점 값에서 저정밀 정수형 데이터 타입으로 변환해준다. 이를 통해 모델의 메모리 사용량은 줄이고 추론 속도는 높일 수 있어, 엣지 시스템에 AI 모델을 배포할 때 특히 효과적이다. 양자화는 수치 정밀도의 일부 손실을 수반하지만, 실제 운영 환경을 대표하는 입력 데이터를 활용해 모델을 보정하면 실시간 애플리케이션에서 허용 가능한 수준의 정확도를 유지할 수 있다.
예를 들어, ST마이크로일렉트로닉스(STMicroelectronics)는 매트랩(MATLAB) 및 시뮬링크(Simulink)를 활용하여 STM32 MCU에 딥러닝 모델을 배포하는 워크플로우를 개발했다. 엔지니어들은 모델 설계 및 학습을 시작으로, 하이퍼파라미터 튜닝과 지식 증류(Knowledge Distillation)를 통해 모델 복잡도를 줄였다. 이후 사영을 적용하여 모델의 차원을 줄여서 파라미터 수와 계산 복잡성을 감소시켰고, 양자화를 통해 모델 파라미터와 활성화 값을 8비트 정수로 변환하여 메모리 사용량을 줄이고 추론 속도를 향상시켰다. 이와 같은 2단계 압축 접근 방식은 자원이 제한된 엣지 하드웨어에서도 실시간 성능을 유지하면서 딥러닝 모델을 배포할 수 있게 한다.
◇ 엣지 시스템에 AI 모델을 배포하기 위한 모범 사례
사영과 양자화 같은 모델 압축 기술은 임베디드 타깃 시스템에서의 AI 모델의 성능과 배포 용이성을 크게 향상시킬 수 있다. 그러나 압축 과정은 정확도에 영향을 줄 수 있기 때문에, 시뮬레이션과 하드웨어 인 더 루프(Hardware-in-the-Loop, HIL) 검증을 활용한 반복 테스트가 모델이 기능적 요구사항과 자원 제약 조건을 충족하도록 보장하기 위해 필수적이다. 이러한 테스트를 조기에, 그리고 자주 수행하면 문제를 사전에 발견하고 해결할 수 있어, 후반 단계에서의 재작업 위험을 줄이고 임베디드 시스템에 원활하게 배포할 수 있다.
또한, 매스웍스의 통합된 개발 생태계를 활용하면 AI 모델 배포와 관련된 다양한 과제를 해결할 수 있는데, 통합을 단순화하고 개발을 가속화하며 전체 프로세스에 걸쳐 포괄적인 테스트를 지원할 수 있다. 이는 특히 오늘날처럼 소프트웨어 환경이 분산된 상황에서 더욱 중요하다. 엔지니어들은 종종 서로 다른 코드베이스를 시뮬레이션 워크플로우나 더 큰 시스템 환경에 통합해야 하며, 표준 개발 환경과 분리된 플랫폼으로 인해 통합 및 검증의 복잡성이 한층 더 증가하고 있다.
◇ 엣지를 위한 설계: 전력, 정확도, 성능의 균형
임베디드 AI의 미래는, 고성능을 목표로 설계되고, 엣지 환경에서 최적의 성능을 발휘하며, 복잡한 공학 시스템을 구동하는 AI 모델로 발전할 것이다. 엔지니어가 프로젝트를 성공적으로 수행하기 위한 열쇠는 모델 압축에 따른 트레이드오프를 이해하고, 초기 단계에 하드웨어 테스트를 수행하여 AI 적용이 가능한 적정 시스템을 구축하는데 있다. 결론적으로, 엣지 AI 시스템 설계에 모델 압축 기법을 전략적으로 적용하면 엔지니어는 임베디드 장치를 강력한 실시간 의사결정 시스템으로 전환할 수 있다.